本文分享一次真实的线上单节点宕机引发的全系统不可用故障,通过拔网线模拟硬件故障宕机,并通过抓包找到根因。
读完本文,可以深入理解TCP连接的含义和TCP超时重传机制,进而也就明白为什么RPC一定要设置合理的超时时间了。
1、故障现象
IM长连接服务一台容器所在宿主由于硬件故障宕机,引发IM所有用户10多分钟无法建接。

2、分析过程
按照设计,长连接服务一个节点宕机后,会导致连接到该宕机节点的IM客户端App批量断开连接,然后这些断线的IM客户端会尝试重连、多次尝试失败会连接其它的长连接服务节点。其它长连接服务节点是正常的,为啥十多分钟都无法建连呢?
通过客户端的日志,发现故障发生后不久,客户端连接宕机节点失败,就去连接其它正常节点,TCP和TLS握手都成功了,但是Auth请求超时,进而断开连接。重新建连、Auth超时断开。如此重复,一直卡在Auth环节。直到十多分钟后故障恢复时才连接并Auth成功。 监控显示负责Auth处理的imServer线程池满,无法给客户端返回Auth响应。
汇总一下,建连Auth的链路:IM客户端 → 长连接服务longLinkServer → IM业务服务imServer
- IM客户端请求其它的正常长连接服务节点,成功建立了tcp连接
- IM客户端发出auth请求,没有获得响应,超时断开tcp连接,循环往复
- 故障时段imServer线程池队列满,无法处理auth请求,没有给出响应
疑问:imServer为啥线程池队列满?
- IM业务服务imServer相关日志,线程池所有线程长时间(820秒左右)卡住没返回,新的请求堆积在线程池队列里,直到堆满

惊! 820秒左右,为啥imServer调用longLinkServer会卡住800多秒不结束呢?查看imServer调用longLinkServer的代码发现,gRPC调用,业务层没有设置超时时间。gRPC底层是HTTP2,HTTP2底层是TCP长连接。推测:在被调用方longLinkServer突然宕机的情况下,调用方imServer需要很长时间才能感知到TCP长连接断开。
推测毕竟只是推测,需要验证才能实锤。
3、试验验证
模拟故障场景,把测试环境一台longLinkServer节点和本地mac电脑上的长连接服务组成一个长连接服务集群,让测试环境的imServer服务跟该longLinkServer集群通信,正常服务拓扑如下面左图所示,我们通过拔掉本地mac电脑的网线来模拟长连接服务一个节点硬件故障宕机,拔网线后服务拓扑如下面右图所示。将imServer的线程池的线程个数配置为1,以方便观察。
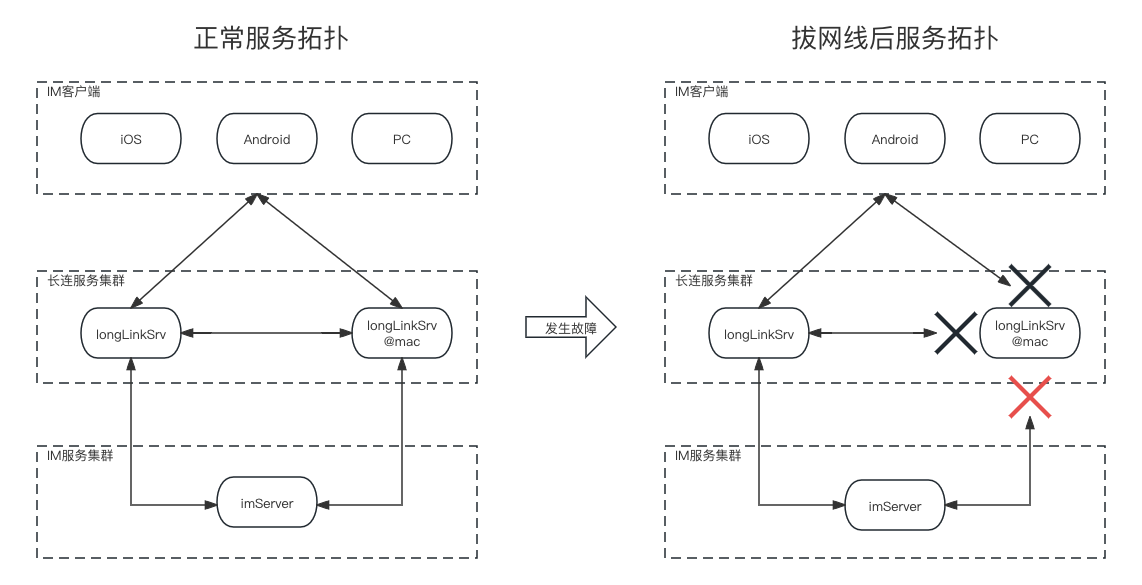
3.1、拔网线试验一: 拔掉网线(模拟硬件故障宕机)
拔网线模拟硬件故障宿主机宕机,复现了故障时的现象:imServer线程池满、客户端无法建连。
试验步骤:
- step 1: 先搭建好上图左侧的服务拓扑,客户端建连正常、收发消息正常。
- 长连接服务集群由一台常规服务节点和一台mac上的长连接服务组成,本地mac方便拔网线,两台节点模拟部分节点宕机
- imServer服务集群单节点、线程池线程数量为1,队列长度为10
- step 2:在imServer上查看到longLinkServer@mac的TCP连接建立成功
10.190.11.68:52400 <-> 172.24.136.17:1215

# imServer正常调用longLinkServer一次耗时9毫秒
[2024-02-20T16:45:47.750+0800][longLinkSrv-caller-1] proc_time=0.009
- step 3: 在imServer上用tcpdump抓取和longLinkServer@mac之间的TCP报文
tcpdump -i eth0 -s 0 'host 172.24.136.17 and tcp port 1215' -w imServer-call-longLinkServer-`date +%s`-case1.pcapng
- step 4: 16:45 拔掉网线,用客户端尝试重新建连失败,已经连接的消息发送失败,复现了故障时的现象。
- 查看imServer线程调用栈阻塞在gRPC请求longLinkServer等待响应的地方
- 查看imServer线程池的队列堆积了请求,新的请求被拒绝
- 查看imServer到longLinkServer的TCP连接,在17:01:34之前,linux内核都认为到longLinkServer@mac的TCP连接都在,在17:01:37时才断开。
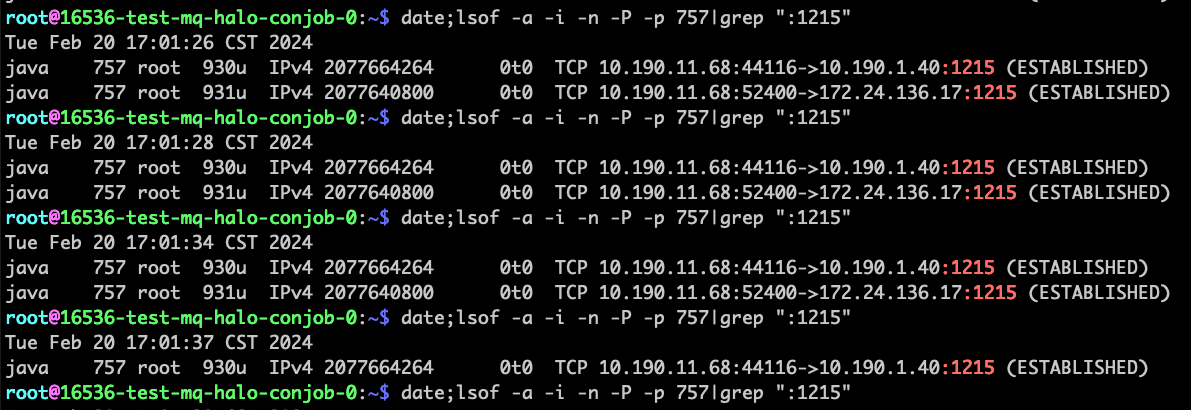
- step 5: 一直等待,17:01服务恢复正常,可以建立连接,也可以发消息了。
查看抓包:
抓包解读:
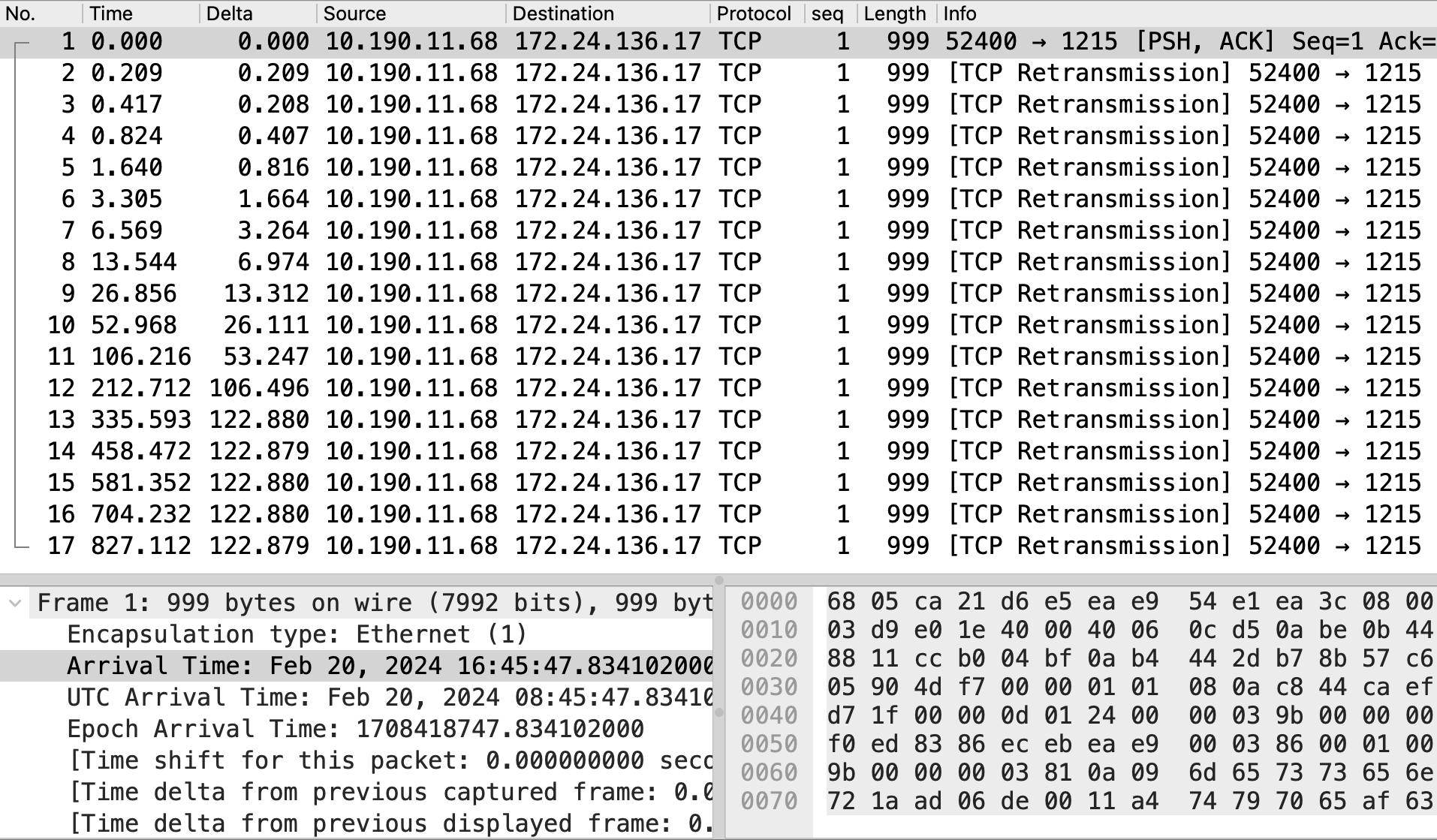
#1号报文显示在16:45:47.834 imServer 10.190.11.68:52400 给 longLinkServer@mac 172.24.136.17:1215 发送长度999字节的TCP报文。
查看imServer的日志发现,调用longLinkServer的总共耗时950.004秒,和tcpdump抓包显示的超时949.092秒匹配,根据处理结束时间和耗时推算:16:45:47.834 ~ 17:01:37.837 = 950.003秒,其中计算出的起始时间16:45:47.834和抓到的原始包的时间匹配,16:45也刚好是拔网线的时间点。之前的推测实锤了。
[2024-02-20T17:01:37.837+0800][longLinkSrv-caller-1] proc_time=950.003713
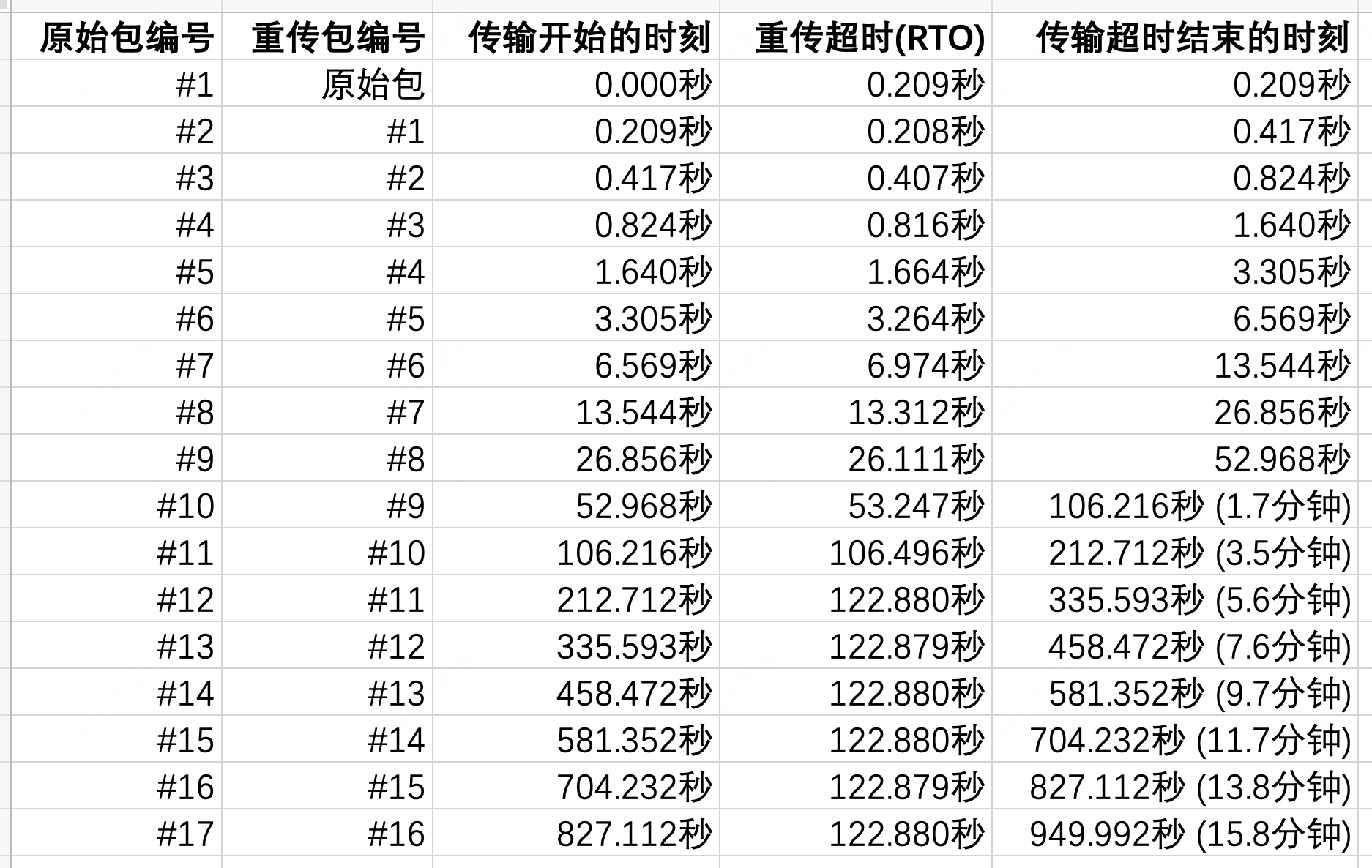
#2号 ~ #17号是重传包,重传超时RTO时间指数倍增,Stevens Sequence/Time图如下,下图中的点在横坐标Time的取值是重传的时间点,间隔倍增,直到达到122秒后不再增加。
#2号 ~ #17号报文都是在重传该TCP报文,一共重传了16次(tcp_retries2=15+1)
3.2、拔网线试验二: 拔网线再快速插上网线(模拟网络抖动)
拔掉longLinkServer所在mac电脑网线,稍等片刻,再及时插回网线,双侧TCP连接完好无损,业务正常处理完成。
查看抓包:
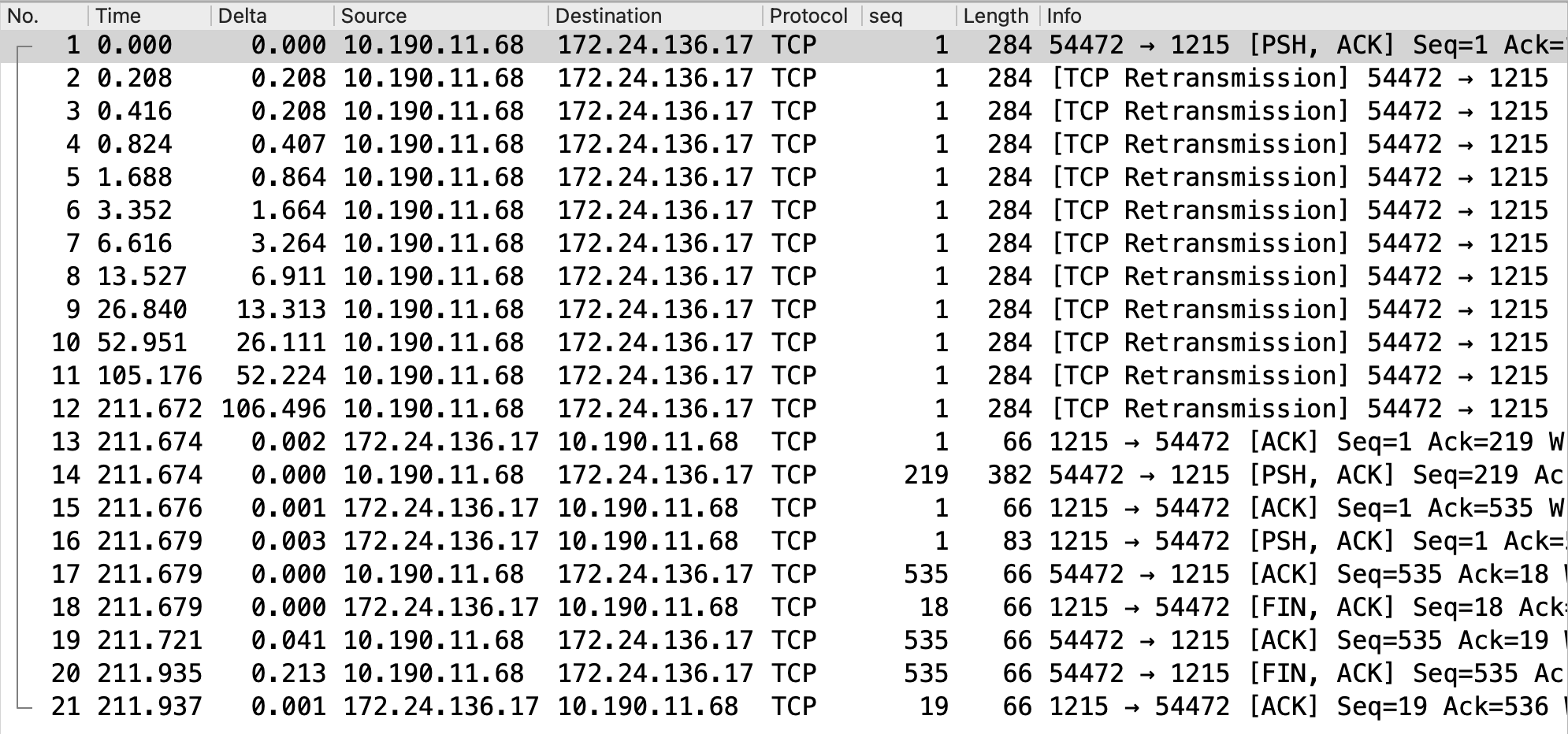
抓包解读:
#1号包imServer 10.190.11.68:54472发出长度284字节的原始包给longLinkServer172.24.136.17:1215
以#1号原始包发出时间为参考时间点,此时网线已被拔掉。
#2号包在0.208秒时开始发出,说明原始包的RTO为0.208秒
#3 ~ #12号包超时时间遵循指数退避原则进行重传
#12号重传包在211.672秒时发出。
#13号在211.674秒收到longLinkServer172.24.136.17:1215的ACK回包,往返耗时2毫秒。说明211.672秒(3.5分钟)时网线已被重新插好。
#14~#17号包是imServer和longLinkServer的gRPC请求往来包。
#18~#21号包是标准的4次挥手断开TCP连接。
总结:17:09 拔掉网线,3.5分钟之内插上网线,插拔网线并没有影响到TCP的连接状态,只是增大了业务感知的延迟,这可能就是传说中的网络抖动导致延迟升高吧。
3.3、拔网线试验三: 拔网线重启服务再插上网线(模拟固定IP漂移)
拔longLinkServer所在mac电脑网线,重启长连接服务进程,再插上网线,imServer侧超时重传,longLinkServer侧linux内核收到重传包后回RST包断开连接。
试验步骤:
-
step 1: 先搭建好试验服务拓扑,客户端建连正常、收发消息正常。
-
step 2: 在imServer上用tcpdump抓取和longLinkServer@mac之间的TCP报文
tcpdump -i eth0 -s 0 'host 172.24.136.17 and tcp port 1215' -w imServer_call_longLinkServer-`date +%s`-case3.pcapng
-
step 3: 17:20拔掉网线
-
step 4: 17:21重启长连接服务进程并插上网线
查看抓包:
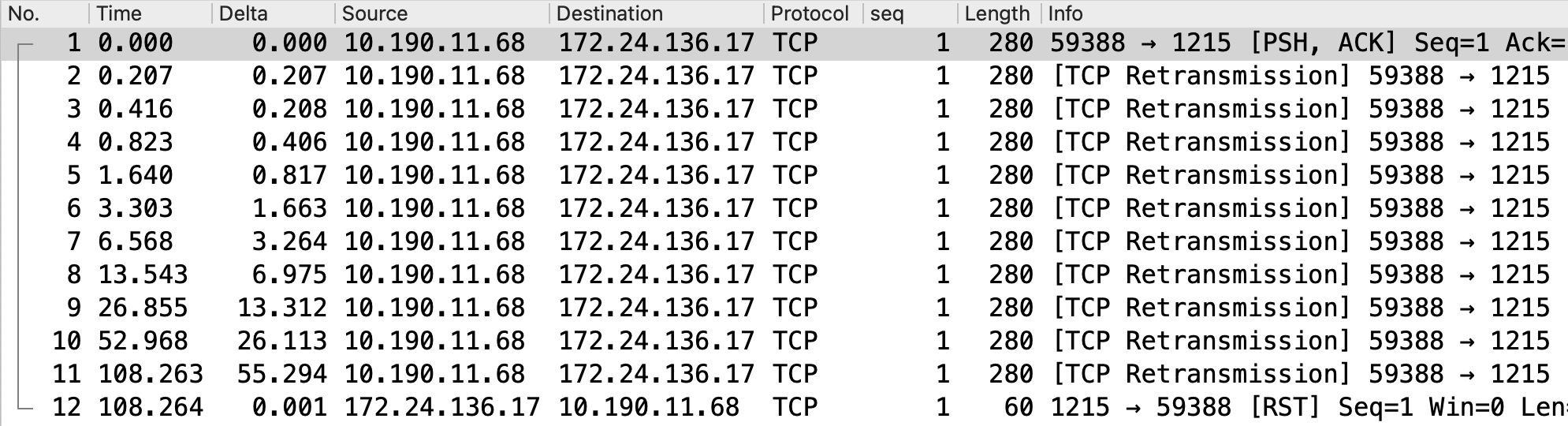
抓包解读:
#1号包imServer 10.190.11.68:59388发出长度280字节的原始包给longLinkServer172.24.136.17:1215
以#1号原始包发出时间为参考时间点,此时网线已被拔掉。
#2号包在0.207秒时开始发出,说明原始包的RTO为0.207秒
#3 ~ #11号包超时时间遵循指数退避原则进行重传。
#11号重传包在108.263秒时发出。
#12号在108.264秒收到longLinkServer172.24.136.17:1215的RST回包,TCP连接断开,往返耗时1毫秒。
4、根因结论
长连接服务一台容器宕机后,因为长连接服务配置的是固定IP漂移,所以没有自动漂移,宕机的longLinkServer容器处于死机状态。
因为没有设置超时,所以IM服务器imServer到宕机的longLinkServer容器的gRPC请求被一直阻塞,耗尽每台imServer的线程池,新进来的请求堆积在imServer线程池的队列中,线程池队列满后,再进来的请求被直接拒绝,于是整个imServer集群都无法工作,因为imServer负责处理客户端建连时的Auth逻辑,所以无法成功新建连接。
因为gRPC使用的是HTTP/2协议,而HTTP/2底层是TCP长连接,当gRPC Server(长连接服务)硬件故障突然宕机时,gRPC Server软件栈(包括操作系统和应用服务)无法做出任何响应。gRPC Client(imServer服务)的TCP协议栈只能超时指数退避重传,重传次数由Cent OS的内核参数tcp_retries2来决定。
CentOS 7.2配置tcp_retries2=15,重传次数为tcp_retries2+1=16次,加上原始包,一共17个包。
root@imServer:~$ cat /proc/sys/net/ipv4/tcp_retries2
15
因为RTO的最小值是200ms,数据中心服务期间的往返时间RTT极低,所以线上环境的RTO取值区间为[200毫秒, 120秒],所以典型重传规律如下:
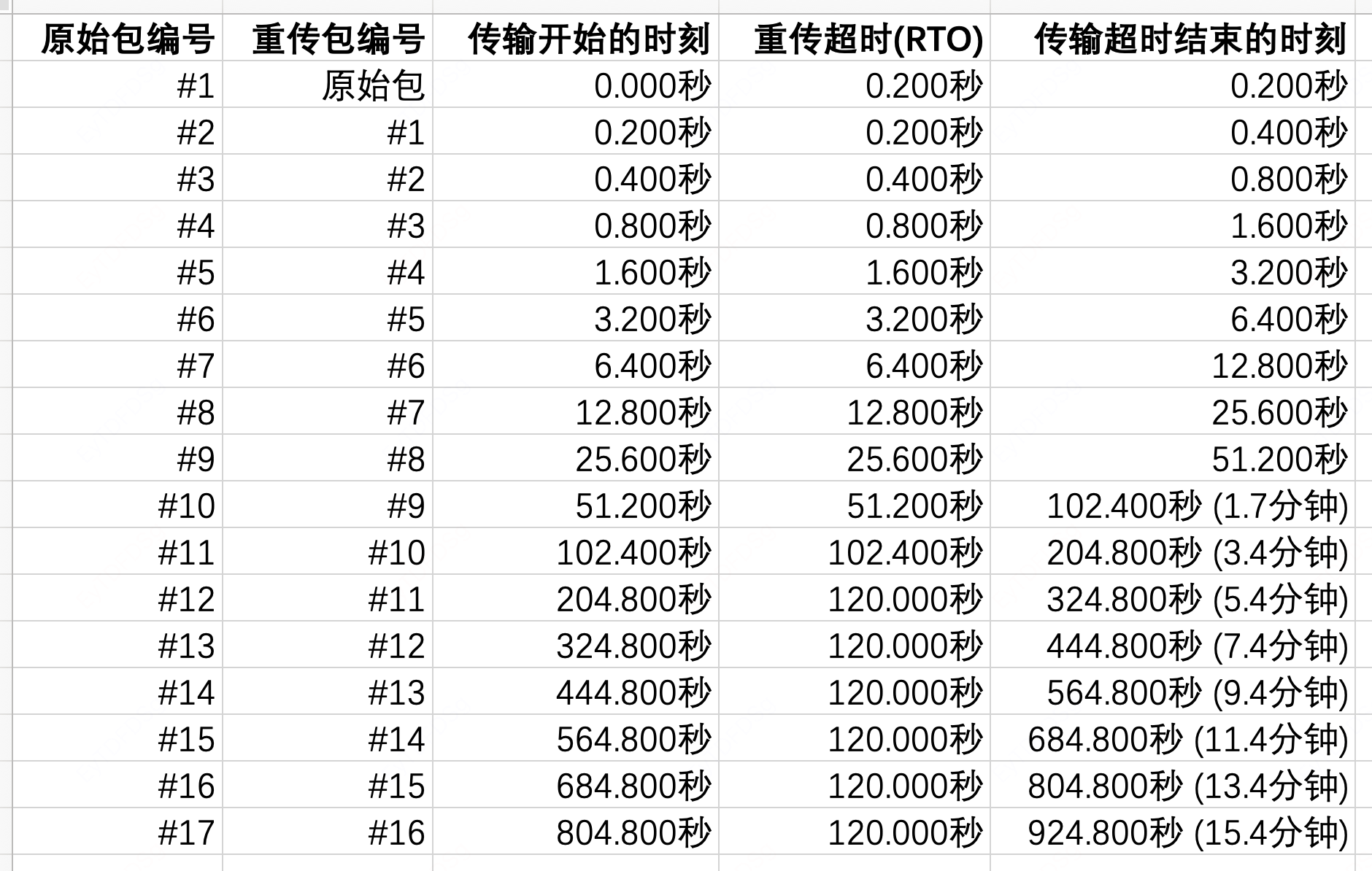
Linux内核一直重传直到超时的总耗时为924.8秒,约15.4分钟。
在我们试验中,RTO初始值208毫秒,是因为测试用的服务器在北京亦庄机房、mac电脑在北京海淀上地,两地之间的RTT增加了8毫秒,RTO也增加8毫秒。
5、引申思考
- 为啥机房内网的机器的tcp_retries2不能调小呢?
猜测:内网的机器也可能远程访问外网服务
- 为啥机房内网RTO_MIN不能从200毫秒调小到20毫秒呢?
猜测:内网的机器也可能远程访问外网服务
-
为啥tcp_retries2=15但是抓包显示重试次数是16次,而不是15次?
-
为啥第一次重试和第二次重试的的RTO都是200毫秒,为啥第二次重试的RTO没有倍增到400ms呢?
6、参考资料
- 《TCP/IP详解 卷1 协议》英文版 第2版
- P650页
binary exponential backoff和net.ipv4.tcp_retries2 - P657页 “Linux内核RTO最小值为200毫秒”
- P793页《TCP Keepalive》
- P650页
